Which AI model should you choose for your business?
Dec 12, 2024

Kevin Bartley
Customer Success at Stack AI

Since the initial release of ChatGPT powered by GPT-3.5-Turbo in late 2022, more large language models (LLMs) joined the competition—112 from established providers and thousands trained by communities across Hugging Face and Replicate. Given the technical complexity and rate of change in this industry, it’s hard for business leaders and developers to quickly grasp which model is the best for each task. This difficulty is compounded when trying to balance accuracy, quality, efficiency and cost.
In this article, we’ll explore some of the best LLMs and AI infrastructure currently available on the market that you can access in your Stack AI projects. We’ll highlight key features, development directions and best use cases to help you choose. And, since the usage costs are included in your Stack AI subscription, you can test each model yourself as you read and see how it fits your use cases.
The best LLMs
Here are the best LLMs in the market, ordered by relevance.
Name | Best for | Context window | Self-hostable | Pricing (per 1M tokens) | Top quality index |
|---|---|---|---|---|---|
OpenAI GPT-4o & o1 | General-purpose tasks, advanced reasoning, coding, mathematical outputs, and multimodal capabilities. | 128,000 | No | Input: $2.50 Output: $10 | 85 |
Anthropic Claude | Safe, reliable responses. Coding, creative writing, and customer-facing chatbots. | 200,000 | No | Input: $3.00 Output: $15 | 80 |
Google Gemini Pro | Handling massive amounts of data, document analysis, summarization, and data retrieval. | Up to 2,000,000 | No | Input: $1.25 Output: $5 | 80 |
Meta Llama | Customization, fine-tuning, and open-source applications. | 128,000 | Yes (open license) | No official API available | 72 |
Mistral | Efficient, smaller models for time-sensitive workflows and low-level intelligence tasks. | 128,000 | Both (closed and open-source available) | Input: $2.00 Output: $6 | 74 |
XAI Grok Beta | General knowledge, coding, and extracting information. | 128,000 | No | Input: $5.00 Output: $15 | 70 |
Perplexity Sonar Online | AI-powered web search, real-time insights, and research tools. | 127,072 | No | Unified $0.20 and $5 per 1,000 requests | 80-85 |
Top quality index (provided by Artificial Analysis), is a normalized average of the following benchmarks:
Chatbot Arena, an Elo-based test where users chat with two separate unidentified AI models and select which is best.
MMLU (Massive Multitask Language Understanding) evaluates knowledge, NLP understanding depth and problem-solving abilities.
GPQA (Graduate-Level Google-Proof Q\&A Benchmark) tests the model on 448 multiple-choice questions across biology, physics and chemistry. It is designed to be extremely difficult: for reference, human PhD holders only achieve 65% accuracy.
MATH evaluates mathematical reasoning capabilities.
HumanEval assesses coding skills by providing a set of unit tests.
AI infrastructure providers
AI infrastructure provider platforms enable faster inference and processing times, fine-tuning and other advanced features.
Name | Best for | Available models | Tokens per second | Time to first token (seconds) |
|---|---|---|---|---|
Together AI | Training, fine-tuning and access to 200 models with privacy and scalability | Multiple leading models (no OpenAI) | Up to 100 | 0.56 |
Groq | Access to LPUs (Language Processing Units) to run LLMs at fast inference speeds | Gemma, Llama, Mistral | 1640 | 0.35 |
Cerebras | Bespoke AI training services, very fast inference | Proprietary, Llama | 2108 | 0.39 |
Replicate | Fast deployment of community-made machine learning models | Multiple custom and community-created models | Not available | Not available |
Hugging Face | Open source development platform offering over 1M models with ready-to-use APIs | Multiple custom and community-created models | Not available | Not available |
Amazon Web Services (AWS) Bedrock | Cloud hosting infrastructure fully integrated with AWS services | Multiple leading models, including Claude (no OpenAI or Google) | 31 | 0.7 |
Microsoft Azure | Containerized AI deployment of OpenAI models, HIPAA compliance and enterprise integrations | Multiple leading models, including OpenAI (no Anthropic or Google) | 28 | 0.56 |
Performance indicators (tokens per second and time to first token) provided by Artificial Analysis. Testing performed with a Llama 3.1 Instruct 70B model.
Deep-dive
OpenAI GPT-4o and o1
OpenAI, the company behind the GPT models, aims to bring AI to everyone, with the ultimate goal of creating artificial general intelligence (AGI). It’s focusing on improving reasoning capabilities, keeping high safety standards and developing commercial partnerships—the biggest one being with Microsoft at the moment.
The top two models currently available are GPT-4o, o1 and their mini counterparts.
GPT-4o is a large multimodal model (LMM), capable of understanding and generating text, audio and images. It’s a balanced model with good performance across general and advanced topics, also offering decent mathematical and coding outputs—overall, a good match for most use cases, especially if you’re just getting started with building with AI.
o1, the newest model family at the time of writing, builds a chain of thought to reason through a problem to the most accurate output. It’s the best model across the board for general and advanced questions, coding and math. But, since it needs time to evaluate the courses of action, it takes longer to give a response—sometimes up to 30 seconds. It’s a great match for tasks that require deep analysis and high accuracy, not so much for time-sensitive workflows.
The mini versions of these models are faster and more efficient, but don’t necessarily offer the best responses when compared with the larger versions. You can use them for tasks that require less intelligence, such as data classification, summarization or simple calculations.
Stack AI has a Data Processing Addendum (DPA) with OpenAI: whenever you use an OpenAI model in your projects, your data is deleted on their servers right after each generation job is complete. However, if you need higher standards for HIPAA or GDPR, Stack AI offers containerized deployment of GPT-4o and o1 via the Azure LLM node, which we’ll cover later on in this article.
OpenAI GPT-4o pricing: $2.50 for input, $10 for output (per million tokens. Free with your Stack AI subscription.)
OpenAI o1 pricing: $15.00 for input, $60 for output (per million tokens. Free with your Stack AI subscription.)
Parameter count: undisclosed.
Maximum context window: 128,000 tokens (\~96,000 words)
Commercial app: ChatGPT
Anthropic Claude

Anthropic’s mission is to create secure, trustworthy and reliable AI models. Unlike other providers who use human reinforcement learning—having contractors upvote the best responses to steer the model’s future outputs—the company uses the concept of constitutional AI where an AI model critiques the responses. This is a more scalable approach to AI safety, offering comprehensive reinforcement without relying on human teams.
As a result, when interacting with Claude, users will experience less toxicity and more useful answers, even if they try to attack or antagonize the model. This makes it a good match when you’re deploying a chatbot that will interact with external users in customer support settings, for example.
The Claude model family is organized in two ways:
By intelligence. In ascending order: Haiku, Sonnet, Opus.
By version. Currently, you can use versions 3 and 3.5.
Not all models were upgraded to the latest 3.5 version, with Opus lagging behind in version 3. This makes Haiku 3.5 and Sonnet 3.5 the best Anthropic models at the moment.
Claude excels in two areas. The first one is coding with a 93% score, on par with OpenAI’s o1. The other one is creative writing with its more natural, human-sounding style, as well as better steerability when compared with other models. The 200,000 token context window helps keep the conversation grounded, great for longer sessions or exploring lengthy documents.
When using Anthropic’s models in Stack AI, you’ll also benefit from the Data Processing Addendum (DPA): your data is deleted from the provider’s servers right after the inference is complete, offering increased data security.
Anthropic Claude 3.5 Sonnet pricing: $3.00 for input, $15 for output (per million tokens. Free with your Stack AI subscription)
Parameter count: undisclosed.
Maximum context window: 200,000 tokens (\~150,000 words).
Commercial app: Claude
Google Gemini

Since the release of Search, Google has been on a mission to organize the world’s information, making it universally accessible and useful. The company already has access to so much data, so the logical step for AI development is to create models with massive context windows. As long as you provide the data sources, you can get impressive response accuracy when providing a very large corpus of data.
The LMM with the largest context window is Gemini Pro 1.5 with 2 million tokens, approximately 1,500,000 words—enough to include the entire Harry Potter saga. Gemini Flash 1.5 is the smaller sibling, offering slightly inferior performance with a 1-million-token window.
These characteristics make the Gemini models better for tasks where you have to search, analyze and retrieve data from collections of long documents or multiple data sources. The intelligence difference between the two models is negligible, so you can safely use the faster Flash for tasks with less data—especially summarization, classification and reformatting. You should still use Pro for answering questions, as its higher reasoning score will yield better results.
Google Gemini price: free API tier available without data privacy. $1.25 for inputs, $5.00 for outputs (per million tokens. Free with your Stack AI subscription).
Parameters: undisclosed.
Maximum context window: 2,000,000 (\~1,500,000 words)
Commercial apps: available in Google Search, Gemini app and NotebookLM.
Meta Llama

Meta redirected some of its efforts from AR/VR into AI, on a mission to use the technology for enabling deeper human connection. It opted for an (almost) open source approach, releasing its Llama models with generous licensing terms: you can use them for free until you reach 700 million users. This is designed to lock out the major competitors Apple, Google and Microsoft.
The Llama family has a long line of models. Here’s a quick guide to understand what each one does based on its name:
In Stack AI, you can access the Llama models from the 3 to the 3.2 version. This indicates how recent they are.
Right after the version, you’ll see the number of parameters. This ranges from 7 billion to 405 billion. In general, more parameters means more intelligence—and also higher computational requirements.
Some models are multimodal, capable of processing images. If so, you’ll see the word Vision right after the parameter count.
If the word Instruct is present, the model was fine-tuned for common tasks such as summarization, question answering and similar use cases.
Finally, Turbo means the model was optimized for efficiency and speed.
In terms of quality, the Meta models are very close to OpenAI’s. The Llama 3.1 405B leads the family, equivalent to OpenAI’s GPT-4o across almost all benchmarks, only behind in math and coding. This makes Llama a great model for customization, offering great baseline quality that you can tweak with fine-tuning. While Stack AI doesn’t offer a native framework to do this, you can connect any of your tuned Meta models into the platform and use them in your projects.
Meta Llama price: free but doesn’t include hosting. Multiple versions available for free in Stack AI (integration on the platform provided by Together AI).
Parameters: up to 405 billion.
Maximum context window: 128,000 tokens (\~96,000 words).
Commercial apps: Meta.ai
Mistral

Mistral, a promising French company with $1.05B total in funding, is building cutting-edge AI that is safe, reliable, efficient and helpful. Unlike other providers, it’s under European Union jurisdiction. The economic bloc has recently released the AI Act: companies developing riskier models must commit to higher levels of transparency and accountability, while implementing appropriate safety systems.
Under such strict rules, it’s interesting to see that Mistral is focusing on building highly-efficient AI models that outperform larger competitors. Here are the most popular ones available in Stack AI:
The Mistral 7B model beats the Llama 13B model on all benchmarks, only having a little over half its parameters.
Mistral Nemo, a 12B model developed jointly with NVIDIA, is the company’s best small model, a robust all-rounder with a 128,000 token context window. It’s open source, meaning it can be freely fine-tuned.
Mistral Large 2 offers comparable performance to Meta’s largest model, Llama 3.1 405B—with just 123 billion parameters, almost a fourth.
Doubling down on efficiency, Mistral offers mixture of experts (MOE) models. This architecture includes a gating mechanism when processing your prompt, selectively turning on and off parts of the model based on the request. In the case of Mixtral’s 8x22B model, it has 8 experts of 22 billion parameters each. This maintains response quality and accuracy without higher compute and time costs.
Running on similar infrastructure, Mistral’s models can be judged as potentially faster, more efficient Llama models—but less customizable, as not all are open source. They offer a robust performance/quality ratio when compared with OpenAI’s, but never quite beats them. They’re a good match for time-sensitive workflows that automate low-level intelligence work, but might turn out to be inconsistent for more critical, reasoning-heavy use cases.
Mistral Large 24.11 pricing: $2.00 for input, $6 for output (per million tokens. Multiple versions available for free in Stack AI.)
Parameters: from 7 billion to 123 billion parameters.
Maximum context window: 128,000 tokens (\~96,000 words)
Commercial app: Le Chat Mistral
XAI Grok

Owned by Elon Musk, XAI is speed and scale combined on a quest for “maximum truth-seeking”. It released 6 powerful models since its founding in March 2023. In just 122 days, the team assembled a hundred thousand NVIDIA H100 GPUs into one of the most powerful AI training systems globally. The trend is set to continue as the founder seeks to challenge OpenAI and other competitors for the top spot in the race.
Grok Beta (a version of Grok-2) offers above-average performance across all benchmarks, especially general knowledge, coding and extracting visual information from documents. Despite claims that it responds with a bit of wit—a feature of the fictional encyclopedia Hitchhiker’s Guide to the Galaxy in Douglas Adams’ universe, one of the inspirations for the model—our testing shows consistent, sober responses across the board. Still, be sure to conduct your own testing to understand what’s the interaction between your use case and the model.
Since it’s a relatively recent model and that its major deployment is on the X social media platform, there aren’t a lot of clear-cut use cases for Grok, especially with other more established options on the market. However, it’s definitely worth keeping an eye on XAI for now.
XAI Grok pricing: $5.00 for input, $15 for output (per million tokens).
Parameters: undisclosed.
Commercial app: Through API, or X, formerly Twitter (Premium and Premium+ subscription required, uses posts available within the social media platform to generate answers)
Maximum context window: 128,000 tokens (\~96,000 words)
Perplexity
Founded in 2022, Perplexity is an AI-powered search engine that generates answers by looking up results on the web. It aims to democratize access to information offering a conversational experience. At the start, it relied on OpenAI's GPT-3 and web searching tools to provide answers. Now, the company expanded the integration to Claude 3.5 and tuned a couple of Meta’s models to further improve the results.
In Stack AI, you can access both Sonar Online Large and Small, receiving the search results directly within your projects. It’s an alternative to using the Google Search knowledge base node, offering a more processed summary of search results. It’s a great match as part of a comprehensive research tool or to quickly provide real-time insights to any workflow.
Perplexity Sonar Online Small pricing: $5 per 1,000 requests, $0.20 per million tokens. Available for free in Stack AI.
Parameters: between 8 and 70 billion
Maximum context window: approximately 127,072 tokens (\~21,179 words)
Commercial app: Perplexity.ai
AI infrastructure providers
In addition to the major providers, the Stack AI editor includes nodes for major AI infrastructure platforms.
Together AI focuses on efficiency and scalability, helping you fine-tune and deploy models that perform at least twice the speed of original providers. You can choose from a library of 200 models covering many use cases and easily integrate them into your apps.
Groq—not to be mistaken for XAI’s Grok—leverages its LPUs (Language Processing Units) to run LLMs at high speeds, up to 1640 tokens per second, the first one generated 0.35 seconds after the request. It offers developer tools for fast AI model deployment, focusing on efficiency and lower costs as the company doesn’t rely on GPUs.
Cerebras offers the fastest token-per-second count, clocking high at 2,108 tokens, the first one created 0.39 seconds after the request. This is a great match for applications that run multiple AI inferences for each user action or in a model chaining pipeline (using a set of specialized AI models that work sequentially). More than performance, the company offers model training services and access to their AI supercomputers.
Replicate has a collection of (stock and tuned) open-source models that you can further refine with your data. It focuses on easy, fast deployment and scalability–a great match for prototyping AI-powered tools with custom models and then distributing the best ones to all teams within your company.
Hugging Face is an open-source community where users publish their models across a wide range of use cases. You can easily collaborate on development, import existing models and run them on the platform, accessing them quickly via API. While time-consuming to browse, it may offer models for niche use-case—or, at least, a good place to start building them.
AWS Bedrock is part of the AWS offering, fully integrated with all the services of this cloud provider. It offers enterprise-grade features, access to a large list of leading models, including Anthropic’s Claude in an isolated environment—but none from OpenAI and Google.
Microsoft Azure is similar to the above, instead offering containerized deployment for OpenAI’s models, enabling HIPAA and GDPR compliance, among other privacy and security certifications.
Local LLMs
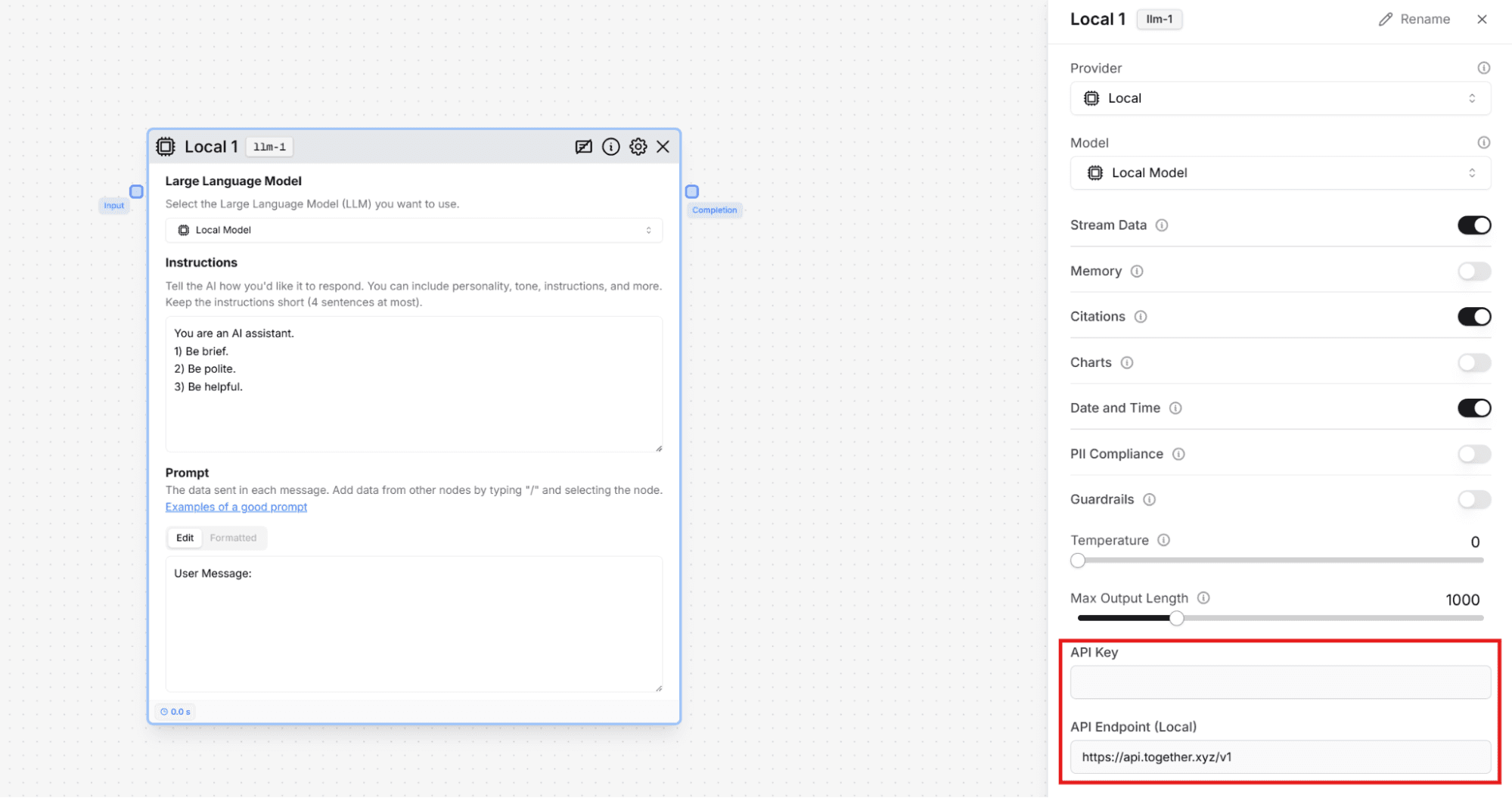
If you have a vLLM or Ollama setup for running models locally, you can use them in Stack AI with the Local LLM node. Set up an API for your local AI model, paste the key in your project and it’ll be ready to use.
Task-specific LLMs developed by Stack AI
To save setup time, Stack AI has a collection of task-oriented custom LLMs for a range of common workflows:
Text-to-SQL converts a natural language prompt into an SQL query with AI, lowering the entry barrier of complex databases for non-technical users, improving access to important data—for example, building an AI sales assistant based on data stored in Snowflake.
Q\&A uses your data sources to answer user questions.
Transcriber performs a given task by reading a document, section by section, provided by the user.
Translator converts text from one language to another.
Which LLM is the Best?
There is no best LLM for every task: each has its advantages and disadvantages depending on your circumstances. Task complexity requires a more intelligent model. Time-sensitive workflows need lower latency responses. Larger amounts of data are a better match for models with a longer context window. And, of course, cost and security are always two factors to take into account.
With Stack AI, you’re not locked into any specific provider. Instead, you can mix and experiment with the latest AI models on the market, testing which are best depending on project needs. All without having to sign up for developer accounts, calling APIs and maintaining internal systems. Get started with a Stack AI free account and start augmenting workflows with AI.
Make your organization smarter with AI.
Deploy custom AI Assistants, Chatbots, and Workflow Automations to make your company 10x more efficient.
Articles









